1. 개요
시계열DB는 영문으로 "Time Series DataBase" 시간을 기반으로 삼은 빅데이터 처리 시스템을 이야기 합니다. 과거 빅데이터를 처리할 만큼의 하드웨어 인프라가 잘 갖춰지지 않았던 시절 센서 데이터를 실시간으로 처리하기 위한 기반으로 만들어졌다고 봄이 옳습니다. 실제로 시계열 DB가 강조하는 대부분의 기능은 실시간으로 데이터를 저장하고, 시각화 한다는 것을 무척 강조하고 있습니다.2. 시계열 DB 시장점유율
일단 데이터베이스 마켓 순위를 보면 시계열 DB는 전체 순위에 들지 못합니다.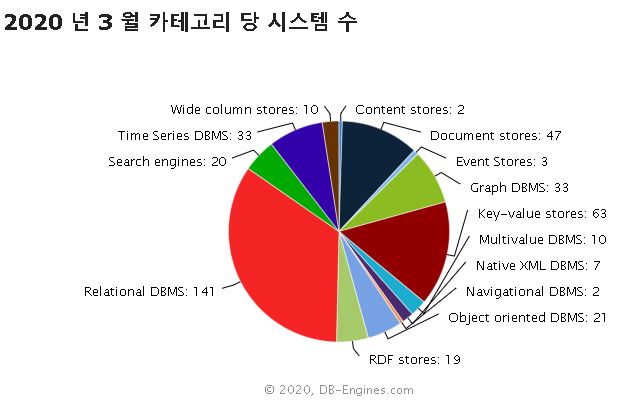
https://db-engines.com/의 자료 인용
https://db-engines.com/ 사이트에서 조사한 전체 시스템에서 RDB가 압도적인 우위를 차지하고 있으며 시계열 DB는 RDB(Relational DBMS)의 1/5 정도밖에 되지 않습니다. 그렇다고 해서 시계열DB가 나쁘거나 한건 아닙니다.
https://db-engines.com/의 자료 인용
지난 2년간의 추세를 보면 압도적인 증가 추세를 보이고 있습니다.왜 이런 현상이 일어나는지는 지난번에 소개해드린 글을 보면 알 수 있습니다.
5.빅데이터 처리 성능. 네트워크 전략
간단히 얘기하면, 물리적으로 엄청난 양의 데이터가 지속적으로 생겨나기 때문에 구세대의 저장장치에 저장했다가 데이터 분석을 위해 꺼내는 데만 해도 수주가 걸릴 만큼 거대하기 때문이죠. 현재 대부분의 데이터베이스 처리 시스템 인프라는 기껏 해야 10Gb/s 속도의 스위치 그리고 hdd 베이스의 저장 장치를 사용하고 있습니다.
서버용 scsi 드라이브라 하더라도 개별 저장소의 I/O 최대 속도는 250MB/s에 불과하고 분산 처리된 파일을 네트워크로 공유하더라도 초당 1.5GB/s에 불과한데 쌓여있는 데이터는 PetaByte이기 때문입니다. 네트워크 속도 최대로 데이터를 추출 하더라도 1PetaByte를 추출하는데 걸리는 시간은 약 9일입니다. 물론 단순계산입니다. 대부분의 데이터 처리 시스템은 데이터 입출력이 항상 일어나고 있기 때문에 I/O부하를 생각한다면 예상 시간은 약 5~9배가 됩니다.
이런 지연 때문에 데이터를 인출하는 것 자체가 어려워지자 이러한 데이터를 분석하기 위해서 시계열 DB는 가장 데이터에 접근하기 좋은 방법을 채택했습니다. 바로 시간을 기준으로 데이터를 분산 처리하고 해당 파티션만 메모리에 올려 분석을 쉽게 만든 것이죠.
3. 시계열 DB의 데이터 저장 구조
뭐 대부분 유사한 형태를 취하기에 알아본 중 가장 간결하게 구조를 보여주는 DB 설명서는 "Apache druid" 였습니다.드루이드 에서는 시간의 분할 단위를 chunk '청크'라고 표현 합니다. chunk는 같은 시간 범위 내에 존재하는 데이터이고, 이 시간 범위 내에서 데이터는 RDBMS의 파티션과 같은 구조로 다시 분할됩니다. (청크를 폴더, Segment를 파일로 생각하면 이해가 쉽습니다.)

https://druid.apache.org/인용 드루이드의 SEGMENT 분할
뭐 이런 구조로 데이터를 분할하는 것은 드루이드만의 기술은 아닐 겁니다. 분명 다른 시계열 DB도 같은 형태를 취하겠죠. 이러한 형태로 데이터를 분할해 저장하면 생기는 이점은 쿼리를 수행할 때 쿼리에 시간을 제약조건으로 사용하여 메모리에 로드할 파일의 양 자체를 줄일 수 있기 때문입니다.RDB의 파티셔닝과 유사하지만, 다른 점은 RDB에선 파티셔닝을 255개 혹은 1024개, 서브파티션을 포함해서 만여 개를 만들 수 있지만, 관리자가 사전에 생성을 해줘야 하는 점이 다릅니다. RDB에서도 최근에는 빅데이터 처리를 위해 자동 파티셔닝을 지원하는 DB가 있습니다. 그 이야기는 다음에 하겠습니다.
과거에는 빅데이터 처리에 SPARK같은 IN MEMORY 프로세스를 중심으로 처리하는 프로세스를 많이 생각했었습니다. 하지만 엄청난 데이터 량을 메모리에 올리기 위한 처리에서 발생하는 I/O 문제 그리고 MEMORY 용량의 한계 때문에 최근 In memory는 유효하지 못한 전략이 되어가고 있죠. petabyte를 메모리를 적재할 수 있는 시스템이 없기 때문 입니다.

데이터 인출 개념
시계열 분할 데이터는 개념적으로 보면 위 그림과 같은 처리가 가능합니다.데이터를 인출할 때 데이터 노드에 간단한 필터 처리를 거쳐 쿼리에 만족하는 데이터만 네임드 노드로 전송한다. 이럴 경우 10Gb/s의 네트워크로도 충분히 차 한 잔 마실 시간에 petabyte급 데이터를 필요 기간 만큼 조회할 수 있을 것 입니다.
드루이드의 파티션 분할 단위는 500MB인데 이를 disk에서 로드 할 경우 3초가 걸립니다. 왜 이렇게 분산파일을 크게 가져가는지 생각해보면 이렇습니다. 파일이 너무 작은 단위로 분산 될 경우 하나의 disk에 같은 시간 파티션이 여러 건 들어있을 수 있으므로, 이럴 경우 동시에 여러 파티션을 불러오면 DISK ARM 점유에 의한 지연이 발생하기도 합니다.

DISK 구조
DISK ARM 지연이란 위 그림과 같이 생겨먹은 DISK 구조 때문에 발생합니다. DISK는 원판 형태로 되어있고, 회전하는 원판의 특정 영역을 ARM이라는 녀석이 읽어오는데 한 DISK에서 여러 SEGMENT를 동시에 읽어버릴 경우 ARM이 동시에 3파일을 읽으려 ARM을 바쁘게 움직이기만 하고 실제로는 순차적으로 읽는 것 보다 지연되는 현상이 발생하게 되는 것이죠. 따라서 DISK I/O가 가지는 읽기 속도가 160MB/s라고 해도 50MB 파일 3개의 파일을 동시에 읽어오면 1초에 끝나지 않고 지연이 발생해서 1.5초 혹은 3초가 되기도 합니다.드루이드에서 파티셔닝 크기가 500MB인 이유는 이런 저런 계산 끝에 최적 값을 찾은 것 이라고 한번 믿어보겠습니다. 혹은 SSD를 기준으로 읽기 쓰기 속도를 맞춘 것 일 수 있습니다.
오늘은 여기까지 써야겠습니다. 다음에 또 뵙죠. 읽어주셔서 감사합니다.
빅데이터 개념잡기 '빅알자'는 여러 페이지로 이루어질 것 입니다.
